1. 动机:为什么“让数据自己分组”?
在当前以大数据驱动的问题导向型研究中,研究者面临的一个核心挑战是:在缺乏显式标签的前提下,如何揭示观测样本之间的内在结构或模式。这种情形在多个学科中普遍存在——生态学中长期遥感像元的时空变化、医学中疾病患者的基因表达谱、环境科学中高频传感器数据、地球科学中遥测剖面数据等都具有典型的“无监督”特征。 聚类分析(Clustering)正是针对这一问题设计的基础方法。它的核心思想是基于某种相似性度量(如欧氏距离、余弦相似度、核函数或图连通性)将样本划分为若干内部相似、外部差异显著的子群(簇)。聚类不是为了预测,而是为了揭示潜在结构、发现未知类别、识别系统异质性或进行数据压缩。在统计方法论上,聚类属于无监督学习范式,其任务可以形式化为如下优化问题:
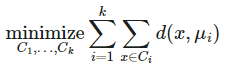
其中 $C_i$ 表示第 i 个簇,$\mu_i$ 是其簇心,$d(\cdot, \cdot)$ 是定义在样本空间的距离函数。 从科研实践角度出发,聚类方法具备如下几方面的重要价值:
- 结构识别(structure discovery):在环境科学、生态系统建模等领域,通过聚类可以发现数据驱动的区域划分、水团结构或功能组分,为后续建模与机制解释提供分区依据。
- 异质性刻画(heterogeneity characterization):在社会科学、流行病学或临床医学研究中,聚类有助于识别群体内部的子结构(如亚型人群),揭示变量之间的潜在耦合或干扰因素的非线性效应。
- 辅助建模(model-based stratification):将聚类结果作为样本分层基础可用于提升统计模型的拟合精度,降低样本间协变量异质性对估计器性能的影响。这在分区域模型估计、集成学习框架中尤为常见。
- 高维压缩与可视化(dimensionality reduction and interpretation):聚类分析常与主成分分析(PCA)、t‑SNE 或 UMAP 等降维方法联合使用,用于高维数据可视化与子群标签构建,提升结果的直观可解释性。
- 异常检测(outlier or anomaly detection):部分聚类方法(如 DBSCAN、HDBSCAN)天然具备检测离群样本的能力,这在自动质量控制与数据清洗中具有实际意义。
需要指出的是,聚类方法本质上仅提供一种数据在“统计结构”意义上的划分,其有效性和可解释性高度依赖于前期变量构造、特征工程以及合理的相似性度量设计。因此,它更像一种研究“起点”,而非终点。在后续研究中,聚类结果应通过领域知识、独立验证或监督学习手段加以印证与深化。 下一节将进入数据准备阶段,详细说明聚类前的数据预处理策略,包括标准化、异常值处理、缺失数据插补、特征选择与降维等内容。这些处理对聚类结果的稳定性和解释性具有决定性影响。
本研究模拟的数据集旨在构建一个具有典型生态分异特征的理想化样本空间,用于聚类算法的测试与评估。数据包括 300 个观测样本,每个样本具有三个关键的环境变量:海表温度(SST)、盐度(Salinity) 和 叶绿素‑a 浓度(Chl‑a),这三个因子在海洋生态系统中具有高度代表性,分别反映热力状态、水体来源与生物初级生产力。
为模拟现实中的水团结构与生态差异,我们将数据划分为三类样本簇,各自的变量分布如下:
- Cluster A(代表近岸春季或温暖高盐区): SST ≈ 18°C,Salinity ≈ 34.5 PSU,Chl‑a ≈ 0.7 mg/m³。该类通常指向温暖、高盐、低营养的水体,具备高透明度与低初级生产力的特征。
- Cluster B(代表远岸中温中盐水团): SST ≈ 12°C,Salinity ≈ 33.5 PSU,Chl‑a ≈ 1.4 mg/m³,模拟远岸或受冷水团调控的中度富营养区,叶绿素水平适中。
- Cluster C(代表河口或高营养输入区): SST ≈ 8°C,Salinity ≈ 31.8 PSU,Chl‑a ≈ 2.3 mg/m³,该类水体多为淡水输入主导,具备高初级生产力和较强的水体混浊性。
这些特征组合反映了现实中不同水团或生态分区可能呈现的典型属性差异。在后续分析中,我们将暂时忽略“真实标签”字段(TrueLabel),以完全无监督的方式进行聚类建模,并通过内部指标和可视化手段判断算法是否成功识别了原有的结构差异。
下面我们正式进入第二部分:数据准备:先洗澡、再聚。



